
AIを判断から行動へ|業務自動化に効くフィジカルAI導入ガイド~ロボットや自動車だけにとどまらないその可用性~

AIを導入したのに、なぜ現場は変わらないのか?
生成AIの登場で「判断」の自動化は大きく前進しました。しかし多くの企業では、AIの分析結果を画面で確認した後、依然として人が手作業で対応しているのが実情です。AIが出した答えを、誰が、どうやって現場のアクションにつなげるのか。この「判断から行動へ」のギャップこそ、業務自動化が思うように進まない根本的な原因です。
本記事では、いま注目を集める「フィジカルAI」の考え方を、ロボットや自動運転といった大規模な話にとどめず、通知・設備制御・システム連携など今日から取り組める身近な領域まで広げて解説します。映像を"言葉で理解する"AI(VLM)をはじめとする画像認識AIの選び方、クラウドとエッジの使い分け、段階的な導入ロードマップなど、非エンジニアの方でも理解できる構成で、フィジカルAIの全体像をつかむことができます。
こんな課題をお持ちの方におすすめです
- AIを導入したが、現場業務の省力化につながっていない
- フィジカルAIに関心はあるが、ロボット導入のような大がかりな話だと感じている
- 映像を活用したAIに興味はあるが、どこから始めればよいかわからない
- 人手不足・熟練者不足への対策として、段階的にAI活用を進めたい
本記事でわかること
- フィジカルAIとは何か ― 「画面の中」から「画面の外」へAIを拡張する考え方
- 業務自動化に必要な3要素「把握・判断・行動」の連携の仕組み
- 映像を「言葉で理解する」AI(VLM)をはじめとする画像認識AI3タイプの特徴と選び方
- クラウドAIとエッジAIの使い分けの判断基準
- 通知→システム連携→設備制御→ロボット活用へと進む4段階の導入ロードマップ
- フィジカルAI実現に欠かせない4つの要件(柔軟性・拡張性・内製化・持続性)
業務自動化の切り札として「AI」が大きな期待を集めているものの…
現在多くの日本企業が、「労働力の減少」「熟練者不足」「安全・品質への要求の高度化」という3つの課題に直面しています。少子高齢化が進む中、どの企業も若い人材の確保に頭を悩ませる一方で、技能や知見に長けた熟練労働者はどんどん年齢を重ね、現場から徐々に退いていきます。
こうして現場から人やノウハウがどんどん失われていくにもかかわらず、安全や品質に関する要求は高まる一方です。そこで現在、製造業や小売業、物流業をはじめ多くの業界で、これまでもっぱら人手に頼ってきた作業を自動化・省力化して、業務の在り方を抜本的に改革する動きが活発化しています。
そのための切り札となる技術として大きな注目を集めているのが「AI」です。ここ数年間でAI技術が飛躍的な発展を遂げたことで、「これまで人手で行っていた作業をAIが代替してくれるのではないか?」との期待がふくらんでいます。
しかしながら、現時点ではAI導入で大幅に人手を減らすことに成功した事例は限定的です。なぜなら、AIはあくまでも物事を判断する「頭脳」の役割を果たすだけで、その判断結果に基づいて人に代わって作業を行う「体」を備えていないからです。

様々な業務を自動化するには「フィジカルAI」の活用が効果的
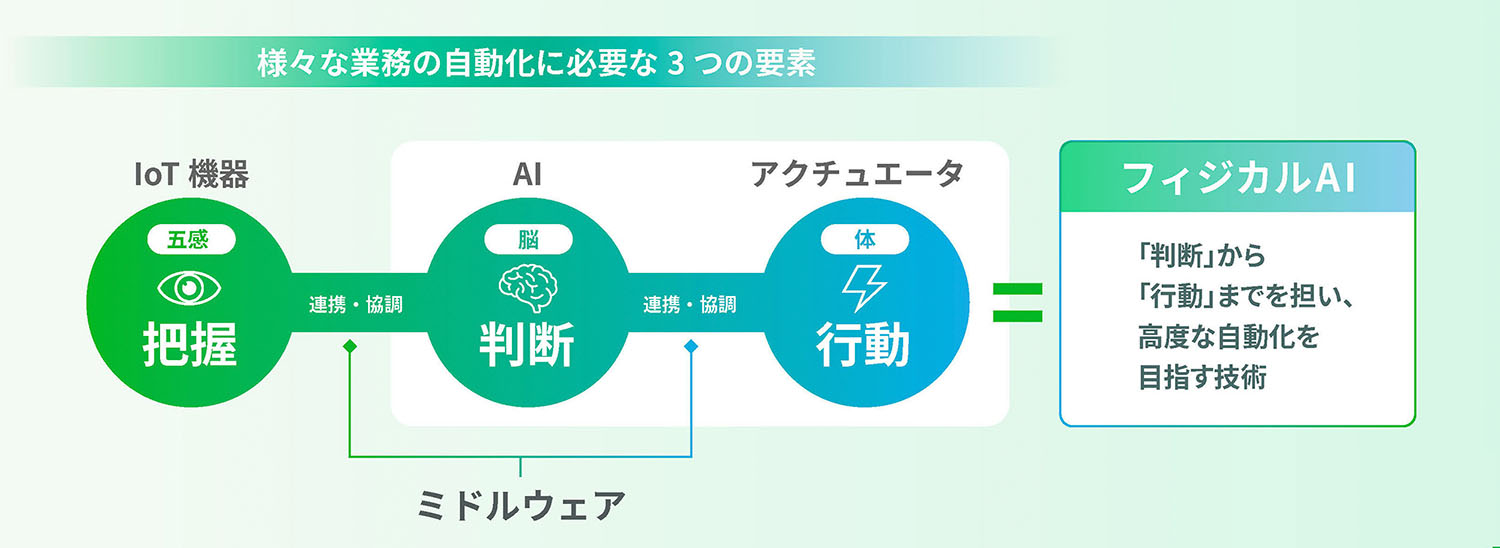
AIを人間の身体に例えると、物事の「判断」を行う脳に該当します。しかし脳が適切な判断を下すためには、五感を通じて情報をインプットし、周囲の状況を正確に「把握」する必要があります。機械やコンピュータで作業を自動化する場合、この「把握」の役割はセンサーやカメラといったIoT機器が担います。
また最終的に機械が人間に代わって作業を行うためには、AIによる「判断」に基づいて、何らかの「行動」を起こす必要があります。いわば人間の「体」に当たるこの機能を担うのが、ロボットや製造機器を駆動するアクチュエータです。
様々な業務の自動化を実現するためには、単にAIを持ってくるだけでは不十分で、この「把握」「判断」「行動」の3要素をすべて揃える必要があります。かつこれらがうまく連携・協調できる仕組み、人間の身体に例えれば「神経」に該当する役割が不可欠です。この部分を担うのが「ミドルウェア」と呼ばれるソフトウェアです。
そして近年、「判断」と「行動」をつなぐ技術領域として注目を集めているのが「フィジカルAI」です。従来のAIが主に判断・分析を中心として活用されてきたのに対し、フィジカルAIはその判断結果を現場の動作や設備制御へと結び付けることで、より高度な自動化の実現を目指すものです。
二足歩行ロボットや自動運転だけがフィジカルAIではない
「フィジカルAI」と聞くと、多くの人は「ロボティックス」や「自動運転」などのユースケースを真っ先に思い浮かべるかもしれません。確かにフィジカルAIが中長期的に目指す先には、人に代わって二足歩行のロボットが複雑な作業を次々とこなしたり、街中を無人自動車が縦横無尽に走り回るような未来が待っています。しかしこうした技術が実用化されるまでには、まだまだ数多くの技術ハードルを乗り越える必要があります。
一方、今すぐにでも実現できるフィジカルAIの領域も存在すると我々は考えています。ロボットや自動車、ドローンのような高度で複雑な仕組みだけでなく、例えば「照明を管理する」「空調を制御する」といったように、比較的単純ではあるものの、物理世界に働き掛けて何らかの行動を起こす仕組みは「広義のフィジカルAI」と呼ぶことができるのではないでしょうか。
もう少し分かりやすく表現すれば、これまでのAIが主に「画面の中」で動くものであったのに対して、フィジカルAIは「画面の外」にAIが進出して、現実世界に直接働きかけるものだと定義することができます。そのように考えれば、以下のようなユースケースもフィジカルAIの一部だと考えることができます。

フィジカルAIにおける「AI(脳)」の役割
フィジカルAIを実現するためには、既に述べたように「脳」の役割を担うAIと、その「体」となって行動を起こすアクチュエータが二人三脚で協調動作する必要があります。そこでまずは、フィジカルAIに適した「最適な脳=AI」の選び方について考えてみたいと思います。
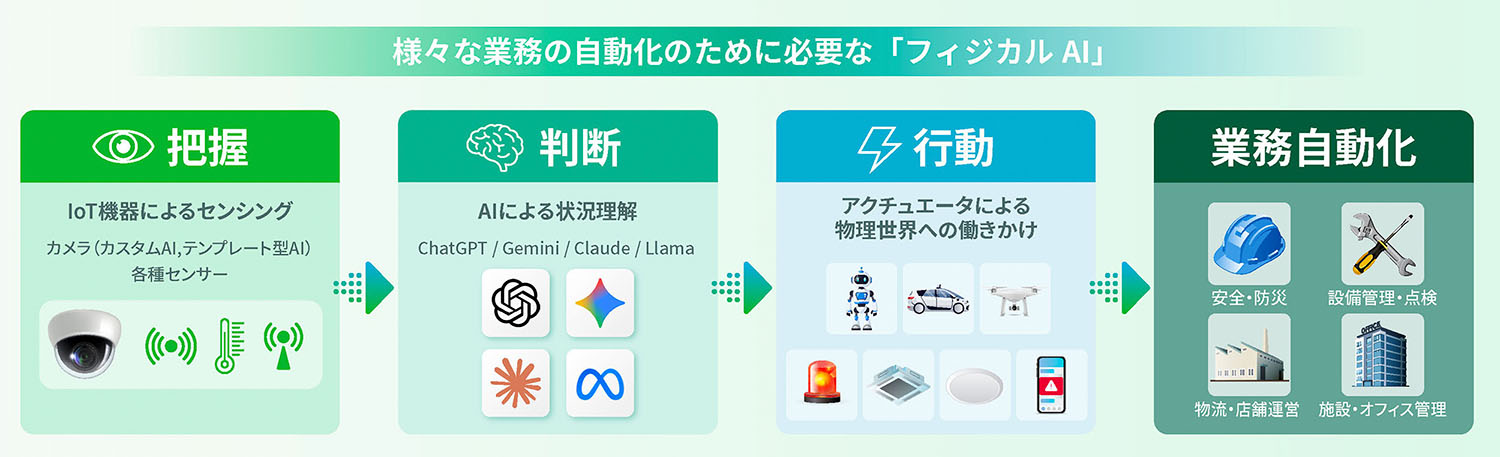
現時点で多くの現場で実用化が進んでいるフィジカルAIの分野の1つが、「画像認識AI」です。カメラが撮影した映像データを画像認識AIが分析・判断し、その結果に基づいて通知や設備制御などのアクションを行う仕組みは、既にさまざまな業務現場で活用されています。
ただし一言に「画像認識AI」といっても、その特性や用途によっていくつかのタイプに分けることができます。具体的には「VLM(Vision-Language Model:視覚言語モデル)」「カスタムAI(独自モデル)」「テンプレート型AI」という3つのタイプが存在し、中でもVLMはフィジカルAIの「把握」「判断」「行動」の3フェーズのうち「把握」と「判断」を極めて効率的に実装でき、かつ一定の精度を達成できる技術として現在高い注目を集めています。
ちなみにカスタムAI(独自モデル)は用途ごとに専用のAIモデルを一から開発する方法で、現場特有のデータを元に学習し、自社専用のモデルを構築します。特定業務に最適化することで、高い精度や再現性を実現できる点が特徴です。またテンプレート型AIは、市場ニーズの高い用途に対して、AIベンダーがあらかじめ開発したモデルを提供するもので、代表例として「AI顔認証」があり、汎用モデルを活用することで、短期間かつ比較的低コストで導入できる点がメリットです。

VLMとは何か?―従来の画像認識との違い
VLMの最大の特長は、映像の内容を理解し、その状況を言葉で説明できる点にあります。これにより、これまで人が目視で判断していた業務の自動化が可能になります。
VLMは、ChatGPTやGemini、Claudeなどに代表される「LLM(Large Language Model:大規模言語モデル)」の発展形の1つです。LLMは人間と同じように自然文を理解・表現できることが大きな特徴ですが、近年のLLMは言語だけでなく、音声や映像なども取り扱える「マルチモーダル」の能力を獲得しつつあります。このうち、映像に関する機能に着目したものがVLMだと理解しやすいと思います。
先に紹介した「カスタムAI」や「テンプレート型AI」は、あらかじめ定めた基準に基づいて対象を分類・検出することはできますが、状況全体を理解したり、柔軟に判断したりすることは得意ではありません。しかしVLMはそれだけでなく、入力した映像についてユーザーが自然文で質問すると、それに対して同じく自然文で答えてくれます。例えば「この映像の中に危険な状況はありますか?」と質問すると、危険の有無とその判断理由について、LLMと同じく自然文で答えてくれます。
この特徴を生かせば、例えば工場内を撮影した映像をVLMに読み込ませて「作業手順に問題がある人はいますか?」と質問すれば、問題がありそうな人を自動的に特定してくれます。また、倉庫内を撮影した映像を読み込ませて「補充が必要な商品はありますか?」と質問することで、在庫補充の要否をAIに判断させることもできます。

フィジカルAI導入の第一歩として、なぜVLMが選ばれるのか
カスタムAIやテンプレート型AIではなくVLMを採用する最大のメリットは、短期間かつ低コストで導入検証を開始できる点にあります。独自に学習データを収集・加工・整理してAIモデルを構築する必要がなく、AIベンダーが提供する汎用モデルをそのまま利用できるため、フィジカルAIの仕組みを短期間で立ち上げることが可能です。これにより、従来は数カ月を要していたAI導入時の検証を、スピーディーに実施できます。
利用方法もLLMとチャットを交わすのと同じ感覚で、映像データをアップロードして自然文でプロンプトを入力するだけなので、機械学習やディープラーニングを活用する際の負担を軽減できます。
一方で、精度の面では、自社の業務に合わせてデータを学習させ、チューニングを重ねたカスタムAIの方が優れるケースもあります。従って、まずはVLMを用いてフィジカルAIの検証環境を素早く立ち上げて、その効果のほどを検証した後に、カスタムAIやテンプレート型AIを用いて本格的な仕組みをじっくり構築するといった具合に、適材適所で使い分けることが重要です。
なお、現在VLMとして利用できるモデルには、利用環境やセキュリティ要件に応じて選択可能な複数の種類があります。

フィジカルAIの効果を高める「AIを動かす場所」の選択
AIの種類と同様に、「どこで動かすか」は、性能・コスト・セキュリティ・運用性に大きく影響します。この「種類」と「場所」の最適な組み合わせを選択することが、フィジカルAIを成功に導く上での重要なポイントになります。
AIを動かす場所には、まず大きく分けて「クラウド」と「エッジ」の2種類があります。クラウドは、ベンダーが構築・運用するクラウド環境上に配置したAIモデルを、ユーザーがネットワーク越しに利用する形態で、高度なモデルを柔軟に利用できる点が特長です。一方のエッジは、工場や店舗、倉庫などのいわゆる「現場」にAIモデルを直接配置し、運用する形態を指し、ネットワークに依存せず、低遅延で処理できるため、リアルタイム性が求められる用途や、機密データを扱う環境に適しています。
AIモデルを運用するには、クラウド上で大量のコンピューティングリソースを投入する必要があると考えられがちですが、近年のPCサーバは処理性能が大幅に向上し、またAIの推論処理を高速化するプロセッサを搭載するモデルも増えてきているため、エッジに配置したサーバ上でもAI処理が可能になっています。
さらに最近ではサーバだけでなく、カメラにも高性能プロセッサが搭載され、AI処理が可能になってきています。一般的に「AIカメラ」と呼ばれるこうしたデバイスが登場したことで、AIモデルの動作場所も年々多様化しつつあります。
重要なのは、用途や現場環境に応じて、クラウドとエッジを適切に使い分けることです。

クラウドかエッジか―自社要件に応じた選択が重要
クラウドとエッジにはそれぞれ特長があり、どちらが最適かは用途や運用条件によって異なります。
AIの動作場所としてのクラウドとエッジには、それぞれ長所と短所があります。クラウド上のAIのモデルは大量のコンピューティングリソースを投入して運用されるため、エッジAIと比べてクラウドAIは、大規模な計算リソースを活用できるため、高精度な分析や高度なAIモデルの利用に適しています。またAIモデルが頻繁に更新されるため、例えば「今日の気温」など最新の情報に基づいた柔軟な判断が可能です。
一方のエッジAIは、クラウドAIと比較すると大規模な計算リソースを活用しにくい場合もありますが、インターネットを介さずローカル環境内で処理を完結できるため、高速かつ安定したスループットを担保できます。またデータを外部に送信しないため、情報保護の観点でも安心感が高いと言えます。さらに、ネットワーク障害の影響を受けにくく、常時稼働が求められる現場にも適しています。
このようにクラウドとエッジにはそれぞれ得意・不得意があるため、フィジカルAIの環境を設計する際には自社の要件に最も適した動作場所を選ぶ必要があります。例えば、PoC(実証実験)の段階では手軽に導入できるクラウドAIでテストデータを用いて検証を行い、本番運用に移行した後はエッジAIで機密データを扱うといった使い分けも考えられます。このように、PoCはクラウド、本番はエッジといった段階的な構成も有効です。
この「AIの動作場所」の選択肢に、既に説明した「AIの種類」の選択肢を掛け合わせることで、自社に最適なAIを選定することができます。

フィジカルAIが実現する「物理世界での自律行動」
フィジカルAIの本質は、AIの判断を現場の行動につなげることにあります。こうしてAIの最適な「種類」と「場所」を選んだら、次にこのAIが下した判断に基づいて行動を起こして、現場のアクションにつなげることで、最終的にフィジカルAIによる高度な自動化を実現できます。ここであらためて、「アステリアが考えるフィジカルAI」について説明しておきたいと思います。
フィジカルAIという用語自体、まだ登場して間もないため、ベンダーやメーカーによって言葉の定義がまちまちなのが実情です。現在AIの世界で最も大きな影響力を持つ企業の1社である米NVIDIA社では、フィジカルAIの具体的なユースケースとしてロボットや自動車を挙げています。また世の多くの方々も、フィジカルAIという言葉を聞いたときに、同じくロボットや自動車のことを真っ先に思い浮かべるのではないでしょうか。
確かにフィジカルAIが目指す中長期的なゴールの代表例はロボットや自動運転車ですが、一方で人の複雑な振る舞いすべてをロボットに置き換えることはそう簡単ではありません。導入コストの高さやメンテナンスの手間、バッテリの駆動時間など、現実的な課題も山積しています。
そこでアステリアでは、フィジカルAIを「画面の外の動作」「ロボットに限定されない物理世界でのアクション実行」と、より広く定義しています。
フィジカルAIがもたらす「画面の中」から「現場」への進化
フィジカルAIの最大の特長は、AIの判断結果を実際の現場のアクションにつなげられる点にあります。
これまでのAIは、データを基に分析・判断した結果を、画面上に表示するまでにとどまっていました。近年注目を集める生成AIも、入力されたプロンプトに応じてAIが画面に出力する文章をユーザーが受け取り、壁打ちや文章の作成・要約といった目的を果たしていました。最近技術進化が著しい画像・動画生成AIも、基本的にはAIが生成した画像・動画を画面に映し出すことが最終目的です。つまり、「画面の中」に閉じていたわけです。
しかしフィジカルAIになると、画面に情報を出力しておしまいではなく、その先に続く「画面の外」の活動までAIが自動実行してくれるようになります。これにより、確認・判断・操作といった人手による対応を自動化することが可能になります。フィジカルAIの本質は、この「画面内から画面外へ」というパラダイムシフトにこそあります。
画面の外の活動にはもちろんロボットや自動運転車も含まれますが、そこまで高度で複雑な機構や仕組みでなくとも、例えば設備の制御や警報の発報、業務システムとの連携などといった比較的シンプルな機械を自動操作して物理世界に影響を与えることができれば、それも「画面の外の活動」であり、フィジカルAIの一形態だと考えることができます。
フィジカルAIの考え方は現場のさまざまな業務で活用できる
フィジカルAIが行う「画面の外の活動」には、さまざまなものがあります。例えば監視カメラの映像をAIが解析し、もし侵入者を検知した際には、パトライトを点灯させたりアラーム音を発するなどして警備担当者に通知するような仕組みが考えられます。あるいは工場設備の映像を基に故障の予兆を検知したり、倉庫の棚の映像を基に在庫補充の要否を判断して担当者に通知したりといったユースケースも考えられます。
こうした仕組みを実現することで、人間が施設や設備を常時監視する必要がなくなり、システムが異常事態を検知したときにのみ人が対応すればよくなります。これにより、多くの企業で今後さらに深刻化すると予想される人手不足への対応を支援するとともに、熟練作業者のノウハウの蓄積・継承にもつながります。さらに、人的ミスの低減にも寄与し、高度な業務要件や安全・品質要求への対応を支援します。
さらには、物理的な機器を動かすだけでなく、SlackやLINE、Teamsといったチャットツールと連携して人に通知を行うような利用形態もフィジカルAIの一種と考えることもできますし、BIツールなどと連携してデータの可視化や分析を可能にするようなシステム連携も、フィジカルAIの一形態だと言えるでしょう。

フィジカルAIにつながる自動化のロードマップ
これまでさまざまなレベルのフィジカルAIの形態を紹介してきましたが、アステリアではこれらの形態は幾つかの段階を踏みながら徐々に進化していくものと捉えています。前項で紹介したような、AIがSlackやLINEに自動的に通知を行い、「人」に対応を促す仕組みは、現場に働きかけて行動につなげるフィジカルAIの第一ステップと言えます。
その次の第2ステップは、通知にとどまらず、AIがシステムに働きかけて、データの自動登録や処理の実行などを行う、APIを活用したシステム連携の段階です。
さらに第3ステップでは、照明機器、空調や工場内の設備などの既存設備と連携し、AIの判断に基づいて現場の機器を直接制御する段階へと発展します。これはフィジカルAIの考え方が現場設備の制御へ広がった形と捉えることができます。
第4ステップでは、AIの判断に基づき、ロボットや自動運転車、ドローンなどに働きかけ、現実空間での移動や作業を自律的に実行するフィジカルAIの段階へと発展します。
この段階では、AIが人や設備を介さずに、物理的な作業そのものを担うことが可能になりますが、本格的な普及には、技術面や運用面を含め、まだ一定の時間を要すると考えられます。
一方で、第1ステップから第3ステップまでのAI活用は、すでに実用化が進んでおり、多くの現場で導入や検証に取り組める環境が整いつつあります。現在、これらのフィジカルAIに向けた段階的なAI導入をサポートする製品はすでに整っており、多くの企業が小さな改善から自動化の効果を積み重ね始めています。

フィジカルAIを実現するために必要な仕組みとは?
ここまで、フィジカルAIの基本的なコンセプトや要素技術、そして今後のロードマップなどについて紹介してきました。では、いざフィジカルAIの実現を目指そうとなった場合、具体的にどのような仕組みを用意する必要があるのでしょうか。これを考える上では、以下の4つが重要なポイントになります。

これら4つの要件が満たされていない場合、導入当初は効果があっても、環境変化に対応できず、やがて使われなくなってしまう可能性があります。フィジカルAIを成功させるためには、AIと現場の動作をつなぎ、変化に柔軟に対応できる基盤を整えることが重要です。
フィジカルAI時代に即したプラットフォーム「Gravio」
フィジカルAIを実現するためには、「把握」「判断」「行動」の3つの要素を個別に導入するだけでなく、それらを連携・協調させる基盤が不可欠です。
アステリアが提供する「Gravio」は、これら3つの要素をつなぎ、フィジカルAI時代に対応するプラットフォームです。
カメラや各種センサーなどの「把握」を担うデバイスと、AIによる「判断」、そして設備制御や通知などの「行動」を、ミドルウェアとして一体的に連携させることができます。
具体的には、カメラやセンサーから取得したデータをAIへ連携し、その判断結果に基づいて、システム通知や設備制御などのアクションを実行する一連の仕組みを、Gravio上で統合的に設計・構築できます。そして「行動」を担うさまざまなハードウェアやソフトウェアとAIとの間の連携も、同じくGravioのプラットフォーム上で容易に構築・制御することが可能です。
また、Gravioはプログラミングを必要としないノーコード環境を提供しているため、専門的な開発スキルがなくても、現場主導でソリューションの構築や改善に取り組むことができます。これにより、前項で示した4つの要件に対応し、フィジカルAIの迅速かつ継続的な導入・運用を支援します。

多種多様なソフト・ハードウェアとノーコードで連携可能
先に挙げた4つの条件のうち、「脳(AI)と体(デバイス)が自由につながること(柔軟性)」と「脳と体を柔軟に変更・組み合わせできること(拡張性)」についても、Gravioは実に多くのAIやシステム、機器をサポートしており、それらの間を自由自在につなぐことができます。
例えばAIに関してはChatGPTやGemini、Claudeをはじめとする主要生成AIサービスはもちろんのこと、エッジで利用可能な各種オープンソースVLMや、さまざまな用途別の画像認識AI、さらにはユーザーが独自に構築したカスタムAIも利用できます。またこれらのAIと連携するソフトウェアについても、SlackやLINE、Teamsなどをはじめとする各種メッセージングツールや、kintoneやMicrosoft365、QlikSenseなど各種グループウェアやBIツールとも連携可能です。
さらにはパトライト装置や音声再生装置、サイネージ機器など、さまざまなハードウェアとの連携インタフェースも備えています。このように、現時点で既に60種類以上もの周辺ソフトウェア・ハードウェアとノーコードで連携可能なため、高度な技術スキルがなくても今すぐにフィジカルAIの仕組みを構築できます。
「変化に強く、長期にわたり安心して運用できること(持続性)」という条件についても、Gravioは特定のハードウェアメーカーやソフトウェアベンダー、AIベンダーの技術に依存することなく、さまざまな製品とオープンに連携できるため、将来の技術革新に素早く柔軟に追随できます。既存の製品や技術についても、新機能の追加や仕様変更に素早く対応できるため、変化に強く長期間使い続けられるシステムを実現できます。
加えて、これまで扱いに若干のコツを要していた画像認識AIも、VLMの登場により一気に身近なものになりました。このVLMとGravioを組み合わせれば、今すぐにでもフィジカルAIを試すことができます。来るフィジカルAI時代にいち早く備えるために、ぜひご活用いただければ幸いです。
































.jpg)



